We will offer the most cost effective “Vanilla Computer Vision” for most needs in the world. From corporate to individuals, through medical and academia. Through our approach - Machine Teaching, and served by a powerfully simple data interface and a playfully efficient user interface, we are designing the only correct method to leverage contemporary machine learning capacity.
CV is everywhere. Many examples on the surface are only due to increase. The drones in Ukraine are playing a
vital role for forces to detect potential threats, objects of interest. Drone delivery for the military also
leverages perception to automate piloting. Startups are helping you find clothing items in retailers catalog
by matching pieces detected in your pictures. AR application often requires some CV to be enabled. The
detection of items held by customers enables flawless check out. In the medical industry CV is helping
doctors identify suspected cancerous cell cavity, and enabling them to surface similar images. On social
media and beyond media safety is a requirement. VCV has a clear impact on growth, revenues, and profit for
ever-growing companies. Individuals should also be able to automatically organise their images to their
concepts and interests, beyond the shy attempt from Apple or Google. For the last 10 years, neural networks
and deep neural networks have been used used for representation learning and have not been beaten by any
alternative. Yet, the large demand is matched by poorly experienced trained practitioners and has a cost of
implementation that could put businesses at risk.
To illustrate our purpose, we will introduce
you to how CV is done today by everyone and what it will look like tomorrow with us. If you would like to
directly look at a specific number, please jump to the section « Machine Teaching ».
What follows is a real life CV example experienced by members of our team. A tech company wished to help its
users find their favorite pieces of clothing in retailers catalogs using phone pictures.
First,
the company had to segment the image to detect pieces of clothing, then apply labels to classify the
detected clothing, and finally classify for gender to finally help finding the most similar items in the
catalogs. A classical detection, classification and similarity search. The company hired 2 PhDs trained in
CV and an ML ops backend engineer and allocated them a lot of capital. They then hired a scrapping company
to get 1.2M “unique” images, who then shared scrapped data to a crowd sourcing service for ground truthing.
With that data, the company trained a model that works.
The models predict the right garment and
equivalent 95% of the time as measured on a fraction of the 1.2M images extracted as a test set. Now they
need to index 5 large retailers catalog of which they must to keep track on stock. The company’s model is
ready. Their app lets users take a picture and suggests similar items from retailers catalog. They get a
unique opportunity to be beta tested and integrated within one of the largest Chinese social media
companies.
The CEO of the social media company himself tests it but keeps being shown woman’s
clothing for male apparel pictures he posted. The team is in emergency mode to fix this through backend
engineering checks, images pre-processing and naming fixes. The ML team reviews the entire model
architecture and their performance reports. They give AWS big money to retrain a bunch of sophisticated
models on their 1.2M images but nothing fixes it. Nothing would until we told them about the 800 women
labelled as men we identified in the training set.
To fix that data quality issue, the company
painfully and hastily built an ugly, Matlab looking UI that presents 1 image and lets you press 1 of 3
keyboard keys to label it in one week using the whole team. Before that, the whole process took several
months. Now the company finds a potential partner in Europe. This time any red or blond-haired person is
almost guaranteed gender misclassification. All over again, the whole team is on deck to correct the hyper
parameters. This time the company could easily see that the training data was 95% asian people and that 30%
of the training set came from the same ~20 models in the streets of Beijing. The images were unique yet not
informative. The company came back to the scrapping and labelling companies, mentioning the 800 women and
the data overrepresentation. The outsourcing companies apologise and commit to “scale” their labeling effort
by creating a task force of 1000 to move fast…
Now things “seems” better. But another fire
arises, now they sometimes get to the right item in retailers catalog, but the item is not available
anymore. They kept working on general computer vision and went to the market thinking they had the core of
their solution. And when they finally got it right, they understood that they did not have a technical
solution to the real algorithmic and computational challenge of their product: how can you keep a very
large, but not normalized catalog of retailers? How do you do a distance search on the model embeddings
vectors?
L`école is offering the most simple and impactful computer vision platform so companies can focus their limited time and resources on their competitive advantage. By following our bulletproof Machine Teaching approach, we can produce calibrated predictions and accurate performance estimation in a few straightforward actionable steps: First we select a representative sample of target images guided by our user. Through the Terminal, the user consistently ground truths a first small bootstrap sample to initiate a first model, which is then trained using an open source deep CNN. The model V1 accuracy might reach 70% but we cannot rely on this, so our user then consistently ground truths a second sample set via the Terminal to verify his model against the V1 prediction. Now he has a test set whose predictions results are inspected, given the selected threshold. Now to improve the model, we do not add data that the model already gets right but use the observed mistakes to find high impact images and let our user teach the machine the correct answer. The Terminal is the one and only UI on AI that can do this. In all and for all, the hard software development, infrastructure engineering, statistical learning sophistication, and complex data pipeline is on us.
Our approach - Machine Teaching - follows the simple bulletproof rule that evaluation of prediction and sample representativity by the subject matter expert is key to ensure reliability and accuracy. Machine Teaching is infusing human expertise, distribution frequency and business consequences into the selection of training data used in ML so that the most relevant outputs are produced by the algorithms. The implication is that Machine Teaching requires a blend of human and computer intelligence to create the optimal training set to guide a learning model with the most efficiency. L`école’s raison d’être is to enable business users to apply Machine Teaching concepts to problems specific to their industry sectors. Lawyers, nurses, city planners, scientists, architects or other subject matter experts can impart important abstract concepts to an intelligent ML system. By including human teachers in the training process, generating results through machine learning becomes faster, safer and cheaper than using data alone. Machine Teaching is our edge, we are designing the perfect system to implement its principles.
The most important requirement with Machine Teaching is subject matter expert engagement and (very) efficient use of their valuable time. To that end, we are building a simple, gamified and efficient Machine Teaching stepwise process ensuring prediction ground thruthing and data clean up by the subject matter expert. Our platform relies on a data interface (connect) to systematically stay in touch with our users’ data and on a user interface (terminal) to engage our subject matter expert and keep them constantly, but lightly, in the loop. The data interface connects to our users’ image stock and streams for continuous analysis. It draws samples to get an accurate, business weighted measure of performance and data representation. It feeds back continuously calibrated predictions to our users’ machines. The terminal is the world’s first at your fingertip user-friendly ML interface empowering the subject matter experts with ML model building. It allows subject matter experts to efficiently ground truth images, extract high impact data outliers, and monitor their models’ performances.
Whether it is legacy data such as years of FMRI images in a hospital databank, or a flow of images from a fast growing social network, we need systematic access to our user’s data to characterize the data distribution frequency along several dimensions (time, impact on business, geography…) and embed key features in the fundamental fabric of the CV models. To that end, our data interface Connect observes, samples and synchronises our users’ data with l`école.ai to bootstrap model building and receive instantaneous predictions feedback. We keep in touch with your data and measure content distribution in real time as it impacts your business.
The UI Terminal is the Machine Teaching interface between the subject matter expert and their ML model. Terminal empowers our users’ expert with a timeline of the model’s progress, clear call for actions when the model needs it, access to high impact datapoints at the tip of their fingers, gamified labelling and actionable performance reporting. Terminal, the first data ground thruthing tool made for the subject mater expert, will produce highly accurate predictive models and drastically reduce the need for large data sets. While other platforms offer customers instantaneous access to thousands of underpaid workers on demand, we are empowering our users’ $200K specialist. With us, there is no need for very large, mostly unchecked, and often poorly distributed datasets.
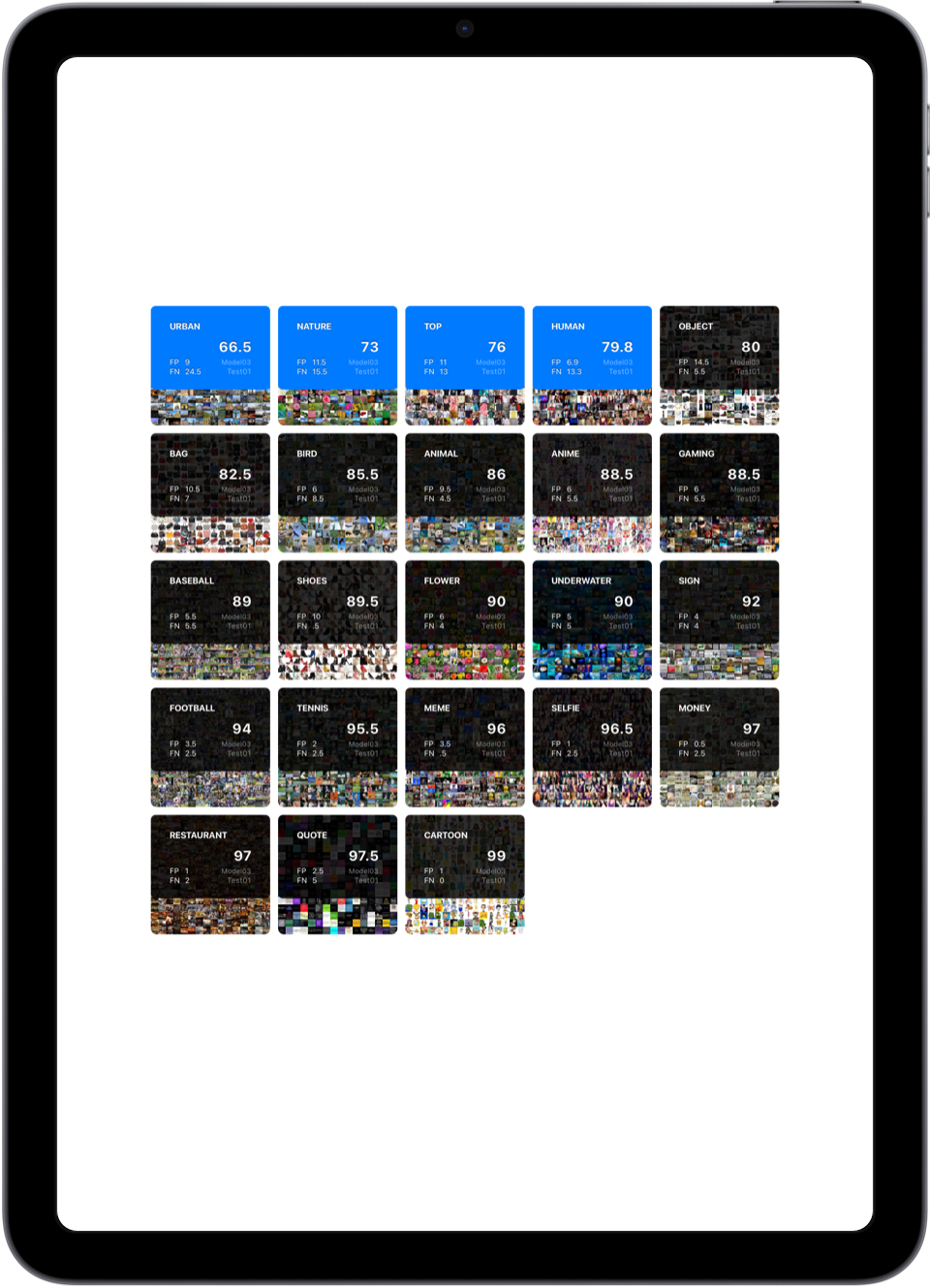
Without worrying about the type of model and the precise architecture and parameters, simply see the concept you wish to predict for classification, detection. Performance driven; several views gives you an overview of your portfolio of concepts and of course, the call for actions.

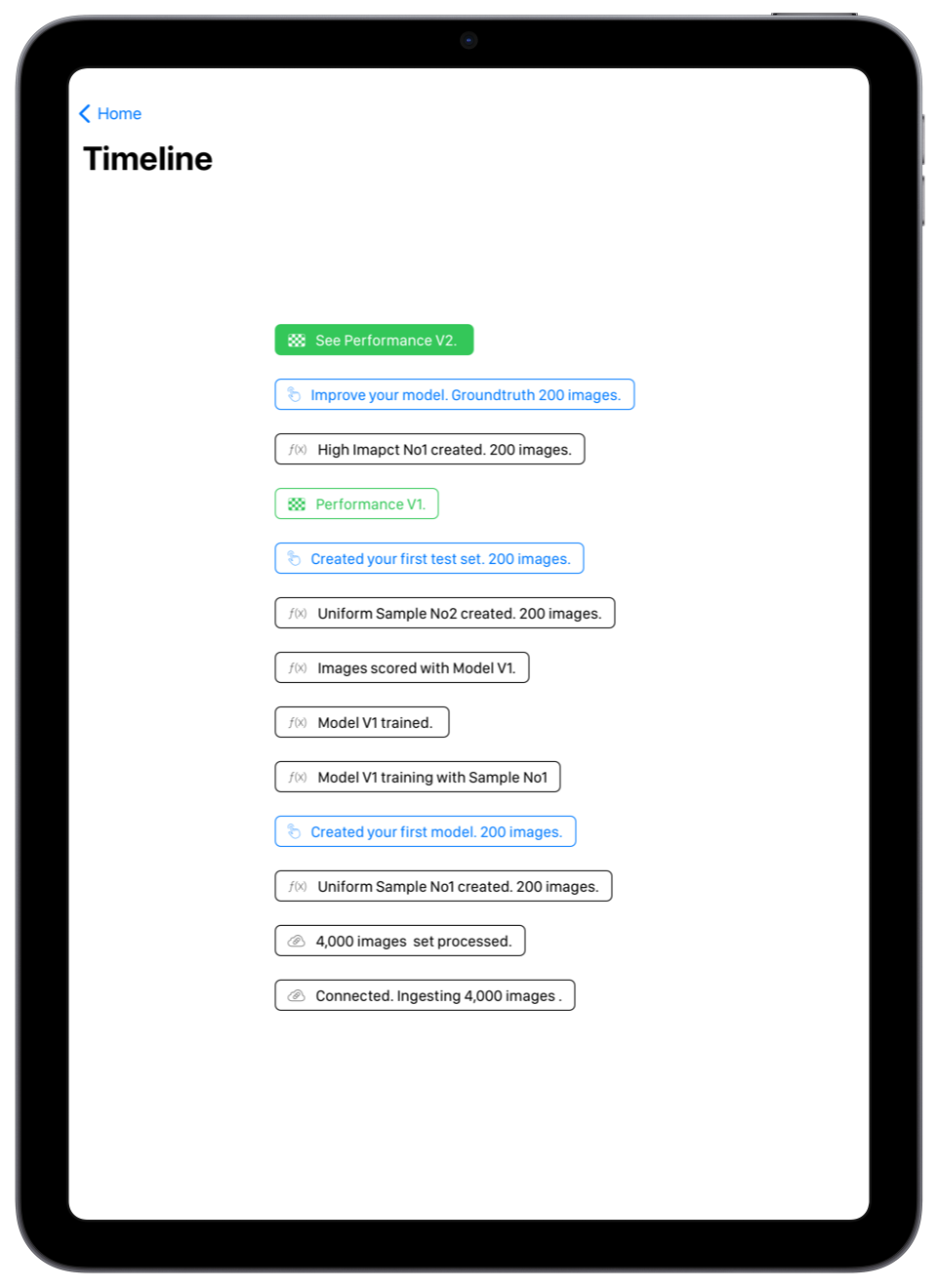
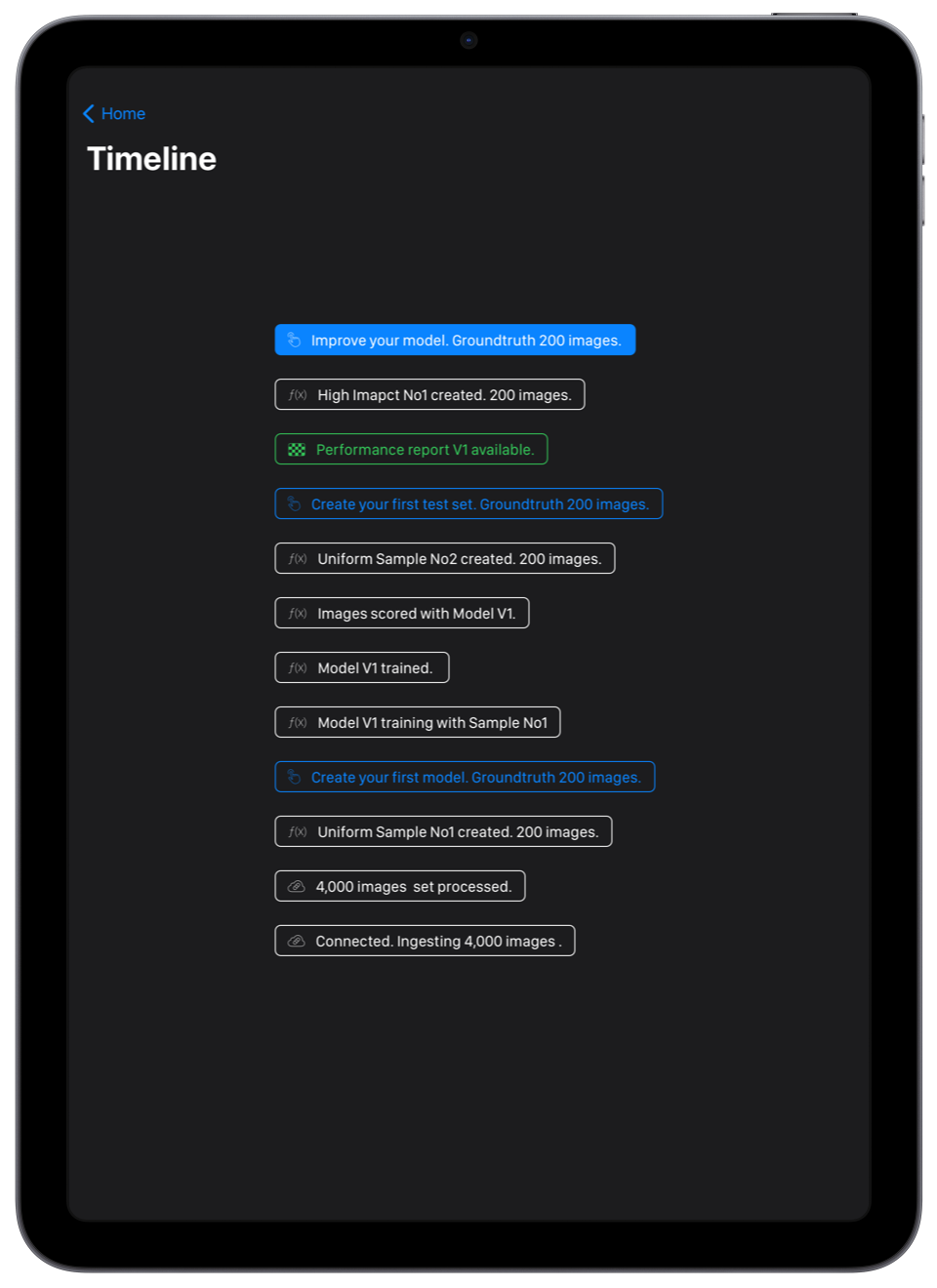
The terminal gives access to the model’s building history and iterations. The user measures the evolution of his model performances depending on previous actions and has a clear view of the timeline ahead until project completion. Finally, while other platform dashboards give no indication on the models evolution and next steps, we empower our users’ expert with clear call for actions when human expertise is necessary. The timeline is your feed, tracking events, performance and threats. With one obsession: fixing a problem. Tracking accurately. Call for action, Status.

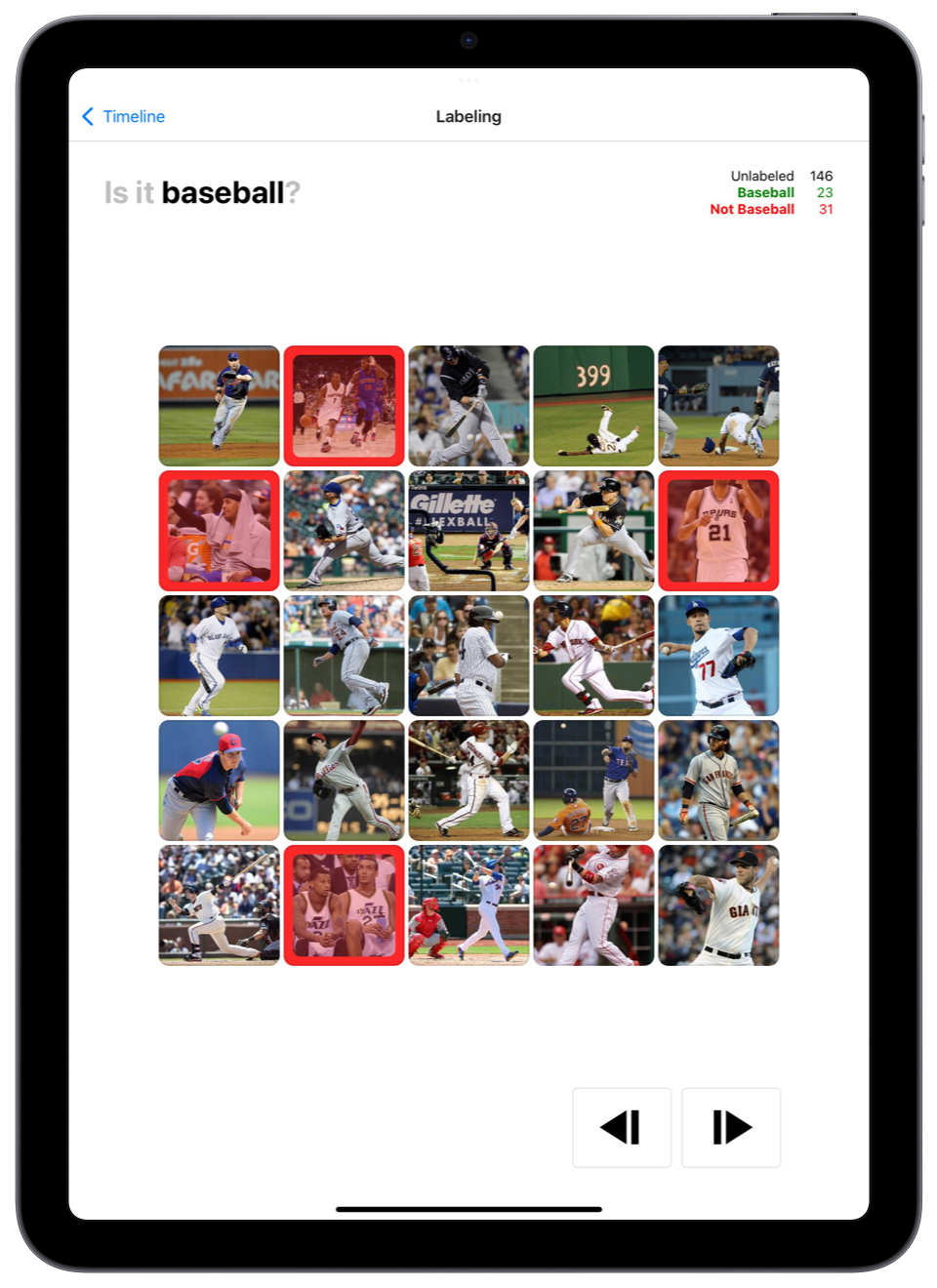
Groundtruthing data is at the heart of machine teaching. When you create a new class you need to predict your need to show your AI enough exemples to get started. As you start to select images, we continuously try to accelerate this process leveraging our general images embeddings. After your AI has trained on this concept for the first time, ground truthing will take even less time.
Explore, Right the wrongs: Continuously browse your groundtruthed data, your treasure. Adjust criteria. Observe your strength and weaknesses. Be able to predict how your model will succed and fail. Anticipate.

We believe that our Machine Teaching approach will reduce the necessary amount of data and associated capital expenditure by a factor of 8, while ensuring labelisation of data and outliers is completed by reliable experts. The former represents 60% of any machine learning project costs, while the latter significantly de-risks CV predictions. Our users gain higher capital efficiency, faster operational deploiement, lighter team footprint, agile resource allocation, improved productivity and increased R&D opportunities. Our business is simple - we want our users to stop overpaying for underperforming AI. Said plainly, we save our clients hundreds of thousands of dollars every year.
We are a fervently creative, inventive, open and collaborative technology company. We are building a revenue stream with an open core for our community of users, driving revenues from added business services such as personalisation, access to our data repository and added security features. Our model is Red Hat, an open source company whose products matter for every other enterprise today. Our pricing strategy will be free for single users with pricing options for teams and entreprises. Today, only the last option is being implemented in the selectied adoption stage.
We are a team of contrarians disrupting an entrenched $B (2022) industry with a bold, yet simple plan. Our business strategy is built accordingly: Adoption (immediately) where we take Crowdflower’s money; Consolidation (≈2 years) where we take money allocated to AWS and finally; Expansion (≈2 years) where we take money allocated to Google. At every step, our first focus is to expand our community of users « La Communauté » to be the backbone of our ML platform.
We target likeminded early adopters in the tech / retail / robotic / medical industries under pressure from limited capital, competitive HR market and high needs for a high quality, amenable, embedded CV solution. Our first clients are present in various fields such as social media, autonomous vehicles, genomics, medical imagery and lidar / radar. During adoption, we will also work with selected academics to co-publish high impact papers and to train the coming generation of engineers and scientists with our tools.
Once the product and architecture are ready, we will mass release it. We want to be popular. We envision a companion phone app for everyone to be able to train their Ai, by themself, together as a community.
With the growth of our early adopters portfolio and the success of some amongst them, we will have proven that our solution is better, more cost effective and the most adapted for CV. Established companies with large datastreams and datastocks will start migrating to our platform. Then we will take CV platforms’ share, crowdsourcing market shares as well as a portion of the AWS share. Moreover, we will bring ethics to large databanks valorization by incentivising our users to stop exploiting cheap labor abroad for data sourcing, data curation and labelling. Estimated TAM > 15B$.
Our approach brings business clarity, user friendliness, transparency and data synchronicity. In essence, we are building the right tool to harness the power and risks coming with deep learning. Our UI on AI that goes far beyond the “no code” BS approach, it puts ground troops in control of their AI business tools. Once we have a market leader offer in CV, we will extend to other types of signals and multimodal analysis. Estimated TAM > 1000B$.
We want to break the barriers between humanity and machines. We are open source and believe in building open AI communities sustained by businesses using our tools. We believe in AI for good. We don’t believe in labor outsourcing and abuse in AI, everyone should be responsible for its own data. We think AI should be fun. We are building our platform to be transparent - we will never get a hold on raw data..
We want to be popular. L`école.ai is building AI tools for humanity through a community of users uploading their data on éo to build personalised models for their hobbies, for their work, for pet projects, for charity, for passion… We want to demystify machine learning by building transparent, freely available AI tools for good. Through an open platform, each user strengthens LAE.net and gets to develop portfolios of data and models that they can share to the rest of the community.