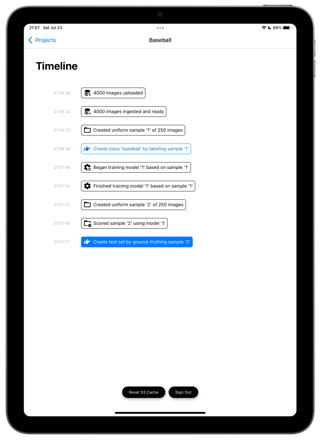
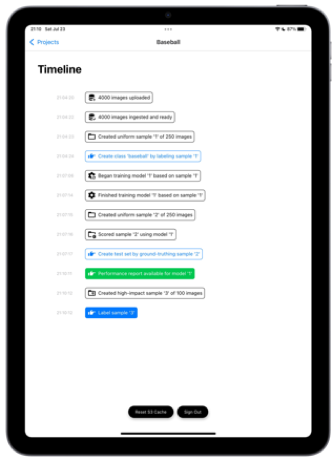
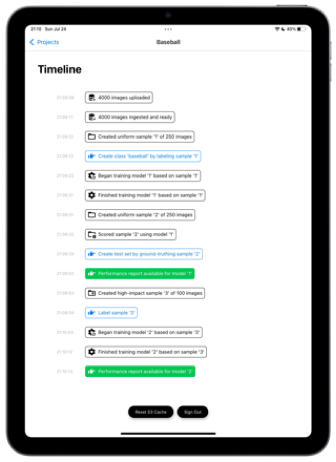
A simple interface to connect your images stock or stream. To do representation learning, we need to draw representative sample. To do so, we will analyse your data distribution (on our proprietary embedding, frequency of posts given day of the week, one day weighting by the post ROI).
Here, we assume the stock of images is representative of the target distribution, a blog about baseball. Hence a uniform sample of 200 images within the 10,000 will do. However in business cases, this sampling method will be sophisticated, with signals such as ROI associated to image… We draw 2 samples: One to bootsrap your fist model the other to test it.
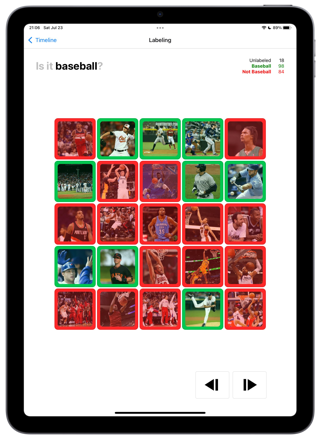
We have ingested your XXX stock images. They are assumed to be a representative sample. We draw 200 images to let you teach your Ai its first concept.
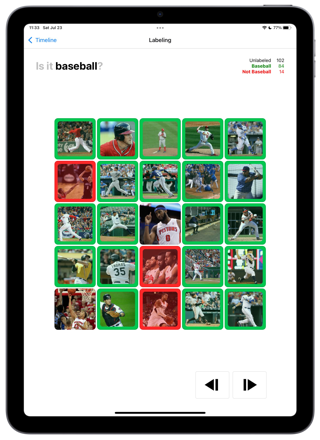
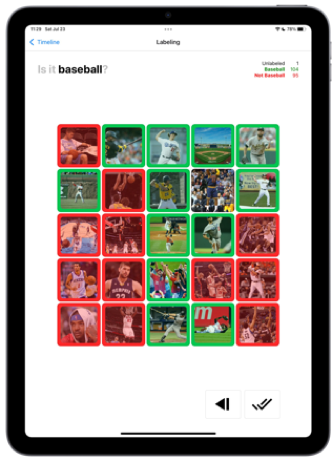
éo ask you a simple question : Is it “baseball”. To ensure visual attention and minimize the risk of misses, you go through images 25 at a time. That is 8 tasks. One finger you choose the Anime images, 2 fingers the NOT baseball. If you select all positives and click next we automatically label the other as negatives. Soon “acceleration”. Soon “gamification for the public platform”
We train your model. Leveraging our proprietary “images knowledge” and embeddings this goes fast. This small model will train in 1min, scoring as well. Could go much faster. Could happen on device..
While we cannot measure the performance of this model yet, as we are missing an independant test set, yet we can visualize what our model has learned. Let`s sort your entire set with the “Anime” score. you can browse and observer the false alarm, the misses… But some reliable numbers would be good.
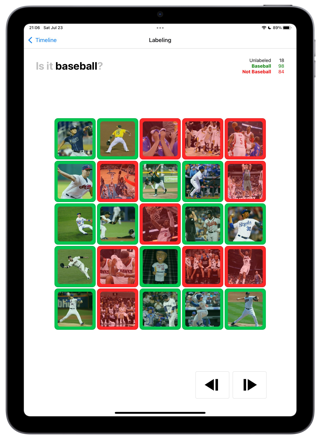
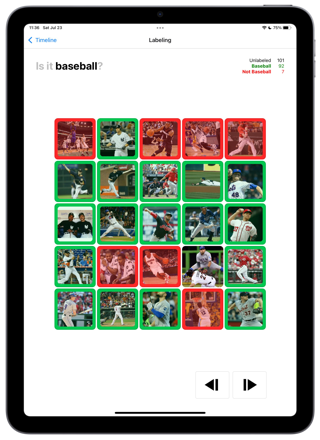
Similarly to the first groundtruthing you need to force a representative sample into “Baseball” and NOT “Baseball”. Except this time, éo can help. The 200 images are sorted. You need to inspect, but you move faster. At least at the begining and the end of the set.
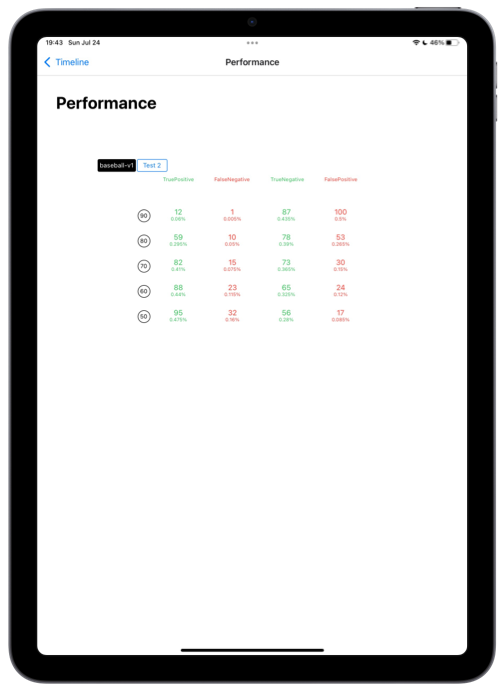
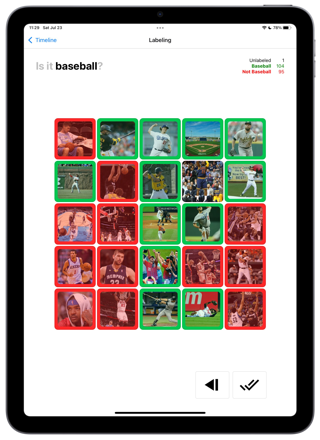
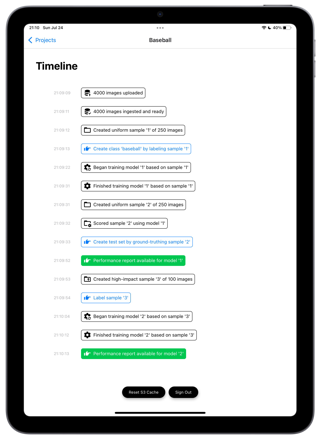
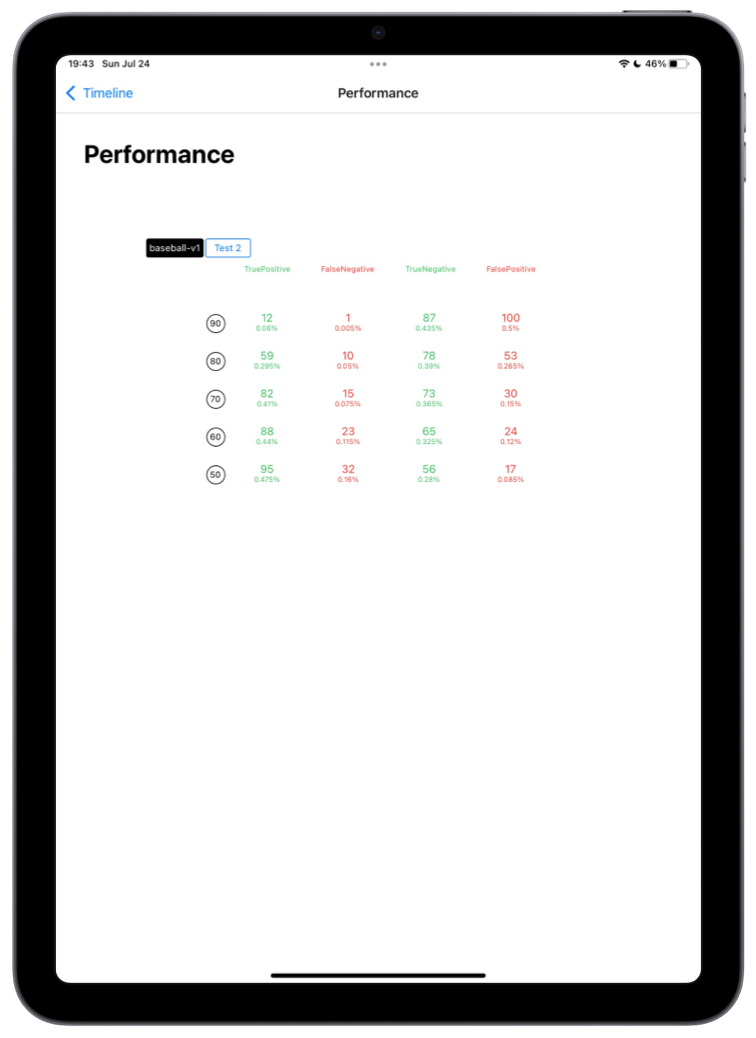
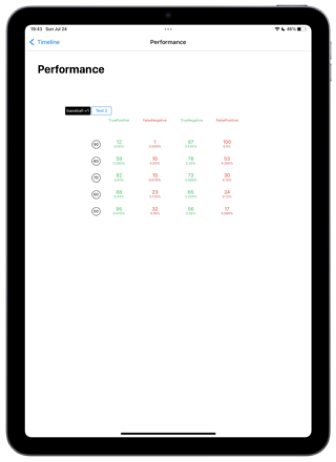
Excellent, you have groundtruthed 200 more images with the help of éo. With this set we can now generate a precise performance report. True Positive, True Negative, False Positive, Fasle Negatives. Given your use, you can choose the best threshold to consume your prediction. And “deploy it” in a click.
L`école considers its éo’s, Ai’s time seriously. And we consider your time and money even more seriously. So we do not want to train éo with images he already “knows” well. It would be stupid. So we are looking for the images where éo has least knowledge. P(baseball) ~ .5. This will be the fastest path to improvement. 80 images.